Appendices
i. The Rebus Personal Library Prototype
About
The Rebus Personal Library Prototype is an exploration of a web-based personal reading and annotation management platform. The goal of the prototyping process is to figure out and help us imagine what meaningful and valuable aspects of academic deep reading need to be supported and made available to academics in their research and writing work.
From a user experience perspective, the prototype takes a very specific line of inquiry: “Can we build rudimentary, web-based digital experiences which return to the user some of the tangible, spatial, temporal, and social experiences of having books in one’s physical environment?” This means the focus was not on the details of reading and annotating books, but the management, collecting, and “living with” of books. Future additions would be some of the more specific reading management needs of academic deep readers, such as grouping by reading intent, prioritization, and scheduling, etc.
In terms of technology, we are driven by a strong belief in the Open Web—with its pillars of open source software and openly licensed content—as the driver of innovation and democratic access to knowledge and tools. To this end, the prototype is built using open web technologies and open source software, and the monographs used for demonstration purposes are openly licensed (Creative Commons). The codebase for the prototype itself is provided as is on GitHub.
Core Elements
Library Overview
The Library Overview gives the user an immediate visual sense of the scale of their collections, as well as hinting at the heft of the books it contains. Book cover thumbnails are sized according to their page counts, giving the user an idea of how big or thick a book is. Grouping and sorting can be done according to aspects such as Date Added, “Read State,” and “Stack.” More dimensions can be added.
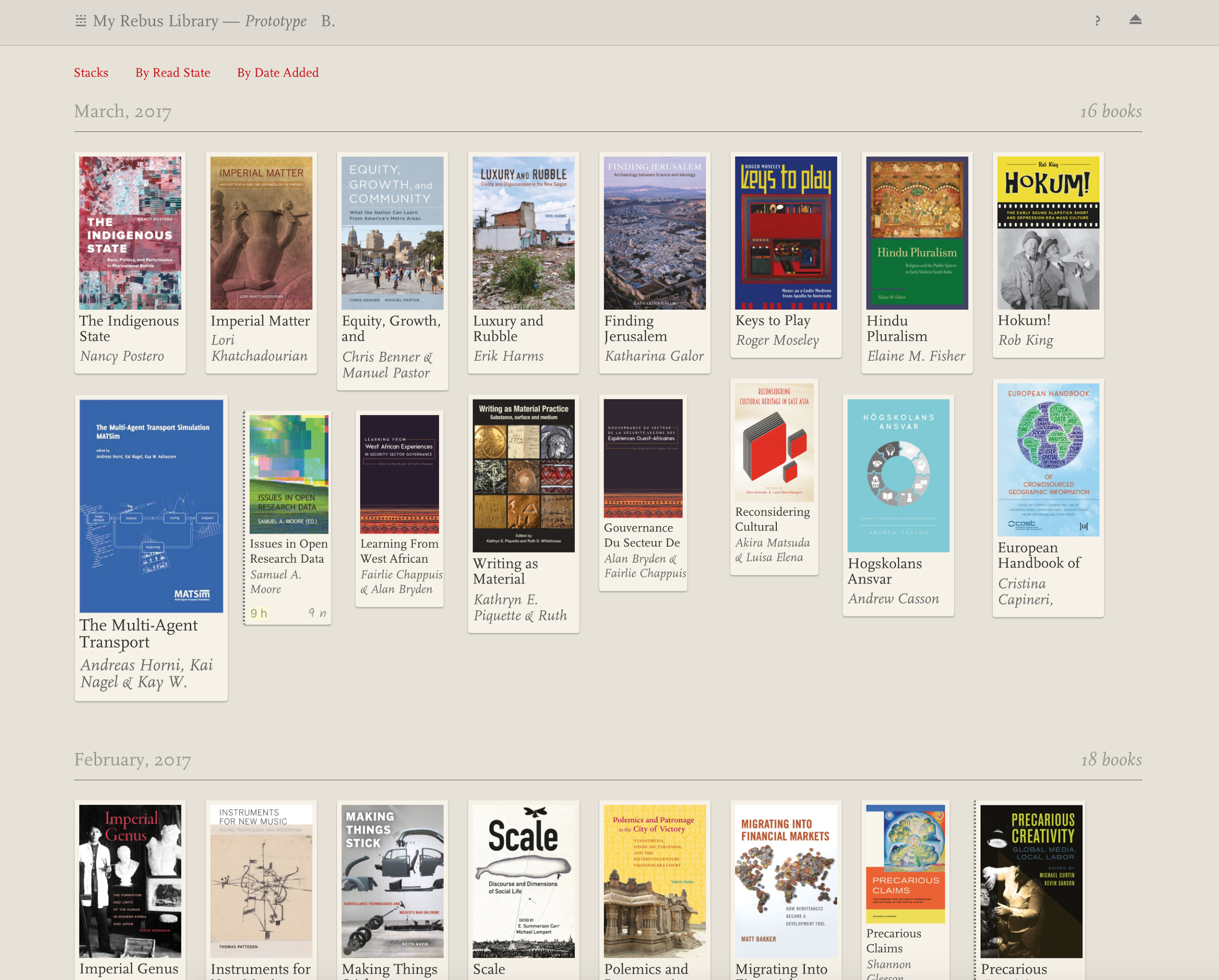
Stacks
Stacks are user-definable groupings of books. They are meant to represent the stacks of books related to specific research projects or any other activity or context the user may wish to define. Stacks are non-exclusive, meaning a book can be “in” multiple stacks at once.
A Stack of books is presented with its relevant metadata, as well as all of a reader’s behavioral traces, e.g.: annotations, notes, etc. This provides “one place” for all context-related (research project, etc.) reading data.
View the “Open Science” stack.

Book and Reading Details
Individual book detail views include relevant metadata, table of contents as well as user annotations and notes. Also displayed are the Stacks the book is part of, as well as a hint of similar books—based on keyword intersections in this case. Easy citation functionality is an example of app-like developments that can be added.
View the book and reading details.

Reading and Annotation
Texts and annotations can be consulted, searched, and read online. Annotation itself would be possible with more development work.

Screen Saver
When the system is not in use, or set to a “display” mode, this screensaver displays a user’s own or popular highlights from books in one’s collection. A new highlight fades into view every five minutes. As a glanceable space, this can be used to surface opportunities for serendipitous discoveries in books one has collected but perhaps not read yet.

Feedback and Future Directions
In order to solicit feedback on the prototype and input on the future direction of development, we shared this prototype with our interview participants. Beyond specific features, we sought more broadly an understanding of what function the product must serve for it to be useful to readers, but also to complement the work of publishers and aggregators, rather than conflict with them.
For more on the future direction of the prototype, see From Prototype to Product.
ii. Interviewees
We would like to thank the following interviewees for their time and insights:
- Heather Coates, Data Librarian, IUPUI University Library
- Anna Creech, Head, Resource Acquisition and Delivery, Boatwright Memorial Library, University of Richmond
- Will Cross, Director, Copyright & Digital Scholarship Center, NCSU Libraries
- April Hathcock, Scholarly Communications Librarian, NYU Libraries
- Stacy Konkiel, Director of Research & Education, Altmetric
- Margaret Smith, Physical Sciences Librarian, NYU Libraries
- Megan Wacha, Scholarly Communications Librarian, CUNY Library
- Amy Brand, Director, MIT Press
- Mark Eddington, Director, Amherst College Press
- Bridget Flannery-McCoy, Editor, Columbia University Press
- Michael Jon Jensen, Director, Technology, Westchester Publishing Services
- Dennis Lloyd, Director, University of Wisconsin Press
- Tony Sanfilippo, Director, Ohio State University Press
- Erich van Rijn, Director of Publishing Operations, University of California Press
- Charles Watkinson, Associate University Librarian for Publishing, Director, University of Michigan Press
- Felix Fuchs, PhD Candidate, Department of English, McGill University
- Mona Gupta, Assistant Professor, Department of Psychiatry, Université de Montréal
- Maya Hey, 2nd year PhD student, Department of Communications, Concordia University
- Pasha Mohammed Khan, Chair in Urdu Language and Culture, Assistant Professor, Institute of Islamic Studies, McGill University
- Katie Kirakosian, Adjunct Lecturer, Department of Anthropology, University of Massachusetts, Amherst
- Zain Rashid Mian, MA student, Department of English, McGill University
- David Wright, Professor and Canada Research Chair, Department Chair, Department of History, McGill University
iii. Online Survey Questionnaire
We would like to thank all those who participated in our online survey. View the questionnaire.
iv. Summary of Rebus’s W3C strategy
Context
A key requirement for the wide adoption and use of digital publications (both in education and trade) is device compatibility. Both EPUB and PDFs have serious limitations here.
- Reading an EPUB requires bespoke applications which may or may not be pre-installed on your device—all of which suffer from significant compatibility issues.
- PDFs are fixed in size and format. Choosing one size for your PDF excludes those using incompatible device sizes.
The platform that offers both significant distribution and pre-established — tested — tactics for cross-platform compatibility is the web. But essential to the use of the web for publications is making sure that it, as a platform, supports the needs of those making publications. To that end we have been participation in the W3C standardization process as they are trying to put together a set of specifications designed to ease the transition from EPUB and PDF to web publications for publishers.
The W3C is only one of many standards organizations responsible for the web. Others include: WHATWG (markup and APIs), IETF (networking), IANA (naming), and ECMA (JavaScript). It is currently the only one of these organizations that has explicitly reached out to the publishing community but is by no means the most important.
Their initial effort is focused on a manifest format (Web Publication Manifest) that adds support for the document structures and metadata that publishers consider essential for their participation in the open web stack.
Our Goals
The fundamental goal of our participation in the W3C is to increase the likelihood of the W3C ratifying Web Publication specifications that both benefit open education and publishing and increase the odds of those specifications being implemented.
The latter is more important than the former. It is more important that we have free and open publication-oriented technologies implemented as a part of the open web stack than to have those technologies standardized specifically by the W3C.
So far, the W3C is the best bet to accomplish these goals but we plan on regularly pausing to investigate if other options would be more effective. Possible alternatives in the long run would be direct participation in the WHATWG (Web Hypertext Application Technology Working Group) who now have de facto control over HTML and many related specifications or a greater focus on open source projects.
Progress so Far
Most of our work so far has been focused on providing a counterweight to traditional publishing interests in the W3C Publishing Working Group. This is not out of some sort of adversity towards the industry but to increase the odds of the Working Group’s Web Publication specifications being broadly implemented. Many of the strategies and needs that drove the development of EPUB directly hindered the adoption of that specification adoption outside of the very limited sphere of a small portion of the market for ebook reading systems.
We are by no means alone in our efforts here. Many of the participants are very keen on putting together a format that is more widely adopted than just in the current publishing industry. This was especially apparent when we contributed to the metadata sections of the proposed specification as our suggestions were met with much broader approval than we had dared to hope.
Currently, the Working Group is evaluating several proposals for a publication manifest format, and there isn’t much consensus on the pros and cons of each.
Next Steps
The next step for the Working Group is to conduct more experiments with the proposed specifications to see if they can be made to fulfil requirements. To answer many of the questions still lingering about the specifications, several assumptions need to be put to test and that requires some of them to be actually implemented.
Most of these experiments can and should be lightweight but the more extensively these formats are tested in this early phase of their life when they can still be changed, the more robust and—hopefully—popular they will be later on.
v. Acknowledgements
The researchers would like to thank the support of the Andrew W. Mellon Foundation, and in particular Donald Waters and Molly McGrane-Cleary.
vi. About the Rebus Foundation
The Rebus Foundation is a Canadian not-for-profit, established in April 2016, with a mandate to foster the development of the infrastructure and ecosystem for open webbooks. The Rebus Foundation received grants from the Hewlett Foundation in August 2016, to promote the creation and consumption of Open Textbooks; and from the Andrew W. Mellon Foundation in Jan 2017 to explore the digital scholarly reading ecosystem. More information can be found at: https://rebus.foundation
